多线程
我相信各位已经从课本上阅读到有关线程的官方概念解释,其中包含了线程的一些性质,我相信不少人会像我一样,在初次见到“操作系统能够进行运算调度的最小单位”这段话时一头雾水,因此,我们也不使用庞杂抽象的定语来为线程下定义,就通过一个例子来简单解释,让我们了解一下它的现象,再通过现象来分析本质。
什么是多线程
我们举一个简单的例子:现在手里有一个程序,它要完成4个工作,每个工作相互独立不存在拓扑关系。
那么如果使用串行执行的话会是这样的:
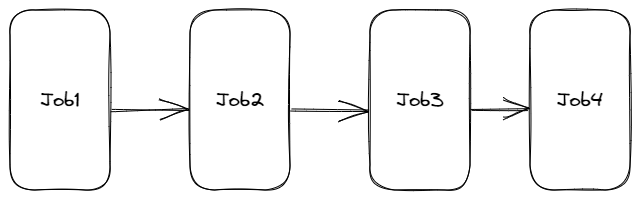
假设每个Job的执行时间都是10秒,那么整个程序运行的总时长是$10\times4=40$秒。
如果我们将它们并行,每个工作都放到不同的线程上同时进行,那么会是这样的:
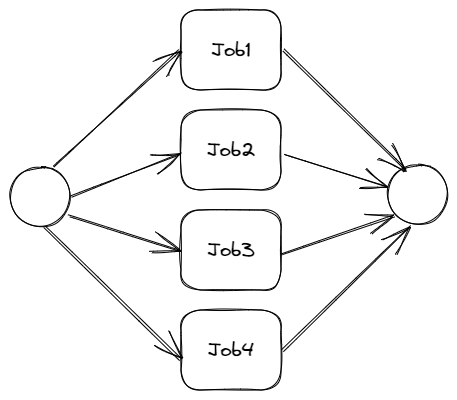
此时整个程序的总执行时长是$\max(10,10,10,10)+N$秒,其中$N$是创建线程和销毁线程的时间开销。一般来说,创建线程和销毁线程时间要远小于10秒,因此我们可以认为如果使用并行策略,那么只需要大约10秒便可以完成串行40秒的任务。
当然上面的这个例子比较理想,完全不相干的多个任务被要求在同一个程序内执行的概率本来就不大,大部分场景下多个任务之间或多或少会有一些拓扑关系,但这并不意味着多线程不重要,相反,合理地划分计算单元以最大程度上利用硬件资源是软件设计开发的一项重要能力。
线程库threading
Python内置了一个线程库threading,该库提供了相当简洁的接口,可以通过简单的示例便可以上手:
这是一段很简单的使用线程库threading的代码,它开启了4个线程,每个线程都有两个形参,分别用来控制循环次数和输出的文本,其中,第一个形参arg1用来控制循环次数,当arg1为1时,threadFunc中的for循环执行一次,为2时则执行两次,以此类推。每次执行for循环时都会输出控制台并延时1秒。
import threading
import time
def threadFunc(arg1: int, arg2: str):
"""线程函数,每个子线程都执行这个函数
Args:
arg1 (int): 参数1
arg2 (str): 参数2
"""
for i in range(arg1):
print(arg1, arg2, i)
time.sleep(1)
if __name__ == "__main__":
th_list = [] # 缓存创建的Thread对象,用来之后统一等待子线程结束
for i in range(1, 5):
th = threading.Thread(target=threadFunc, # 指定了要执行的函数
args=(i, "thread",)) # 指定了函数所需的参数,值得注意的是,最后一个,不要忽略
th.start() # 开始执行线程
th_list.append(th)
for th in th_list:
th.join()
当我们执行这段代码后,我们可以得到一个很简单的结果:
1 thread 0
2 thread 0
4 thread 0
3 thread 0
2 thread 1
3 thread 1
4 thread 1
3 thread 2
4 thread 2
4 thread 3
在所有线程的第一轮执行过程中(i==0),线程1、2、3、4同时输出结果,它们输出和执行的顺序并不一定是创建的顺序。在1秒后,第二轮输出结果出现,此时线程1因为只循环一次便退出,只剩下线程2、3、4。最终在最后一轮只剩下了线程4执行。
当然,threading除了通过指定target目标函数来执行任务以外,还可以通过继承threading.Thread的方式实现:
import threading
import time
from typing_extensions import override
class TestThread(threading.Thread):
def __init__(self, arg1, arg2):
self.__arg1 = arg1
self.__arg2 = arg2
super().__init__()
@override
def run(self):
for i in range(self.__arg1):
print(self.__arg1, self.__arg2, i)
time.sleep(1)
if __name__ == "__main__":
th_list = [] # 缓存创建的Thread对象,用来之后统一等待子线程结束
for i in range(1, 5):
th = TestThread(i, "thread")
th.start() # 开始执行线程
th_list.append(th)
for th in th_list:
th.join()
这里使用TestThread继承threading.Thread并重写了run方法,这样在调用th.start()时会自动执行run(self)方法。使用上述写法同样也可以得到相同的运行结果,大家可以试一试。
上述示例用了类相关的概念,包括类的成员变量、成员函数、继承与重写。
上面的代码我们只考虑了多线程执行的情况,但事实上我们在设计的过程中还需要考虑各种异常场景和同步场景,例如线程的计算结果如何处理返回,子线程的异常如何处理,这也是我们进行并行开发时需要着重考虑的问题。
线程池库
我们在完成上一节学习后就可以认为已经入了多线程的门了,但当我们实际应用时就会发现默认的线程库或多或少会有一些使用不方便的问题:
- 每个线程没有返回值的获取:只能通过容器或全局变量的方式返回状态或结果
- 当并行数量较多时不易控制同一时间运行的线程数量,造成大量时间耗费在资源抢占上。
于是我们就发掘出了Python内置的线程池库。
线程池库介绍
线程池的常见设计思路:任务型、计算器型。
Python的多线程问题
GIL、适用场景、验证、多进程、协程